 The rise of social media has turned our world upside down. Before only companies were publishing information but now everyone can ventilate their views and opinions on the web. People are writing blog post, comments on those of others, write reviews, post on forums, and tweet about all sorts of topics.
The rise of social media has turned our world upside down. Before only companies were publishing information but now everyone can ventilate their views and opinions on the web. People are writing blog post, comments on those of others, write reviews, post on forums, and tweet about all sorts of topics.
This generates a wealth of information that can be mined by companies to discover what people are saying about their brands and even how they feel about their brands. As a company you don’t need to resort to questionnaires any longer. That is if you have the time to sift through the enormous amounts of information, filter out the noise, understand the conversation, find out what is relevant and categorize this so you can analyze it, right? Thankfully this is not the case as we have taught computers how to do this for us.
Teaching computers to read and understand human language is not an easy task. Cultural factors, linguistic nuances and differing context make it very difficult to classify strings of written text. The shorter the text, the harder it becomes which presents a problem when classifying tweets for instance which can be really short.
Detection of bare sentiment and ontology base sentiment
It’s not enough to just determine the sentiment of a document as you also need to know what the document is about and which sentiments relate to the subjects in the document. A basic sentiment detection is to look at the sentiment value of the words in the text and calculate the average value. This way a document can be regarded as negative, neutral or positive. We call this the bare sentiment.
Let’s look at a publication about the brand Apple with the title “iPhone 5 sold out at most of the US stores”.
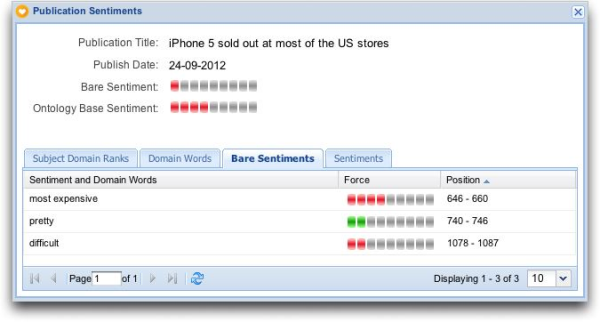
In this example three sentiment words were detected by BuzzTalk. In the left column you see the sentiment words. Positive words are labeled green and negative words are labeled red. The force is shown in the right column. You see that “most expensive” is regarded as more negative than “difficult”. This has been determined by linguist researchers. You can calculate the average force making this document overall negative with a bare sentiment of −1.
Another method in automated sentiment detection is to determine the subject the sentiment is about and relate the detected sentiment based on the meaning of words that commonly occur together in an opinion-oriented text. We call this the ontology-based sentiment. Ontology contains words and word combinations required to define what a piece of text is about. You see that the negative sentiment in this publication relates to the iPhone being expensive (in this case referring to the most expensive model that wasn’t sold out).
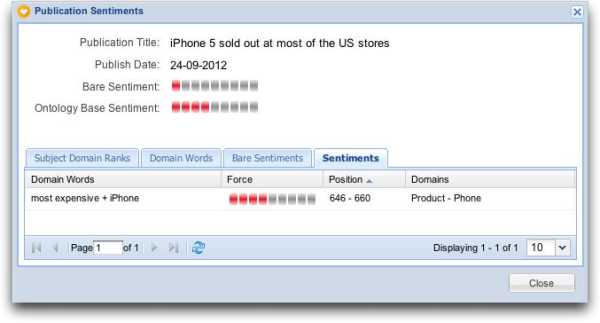
A problem lies in the way we humans use language. We sometimes use sayings that have figurative meaning or we’re sarcastic as in “if this is your darling fragrance please wear it exclusively at home and tape the windows shut”. It’s difficult for computers to understand this so we need to resort to statistics. In order to state something about a subject we need to have a data set that is big enough. Instead of trying to be 100% accurate, you can be for instance 90% accurate by only analyzing a fraction of the data.
Sentiment monitoring
Now we can quickly analyze large amounts of data to determine the overall sentiment and trends in sentiment to aid in decision making about products, services, events and organizations.
Let’s now see how people feel about Apple’s new iPhone 5:
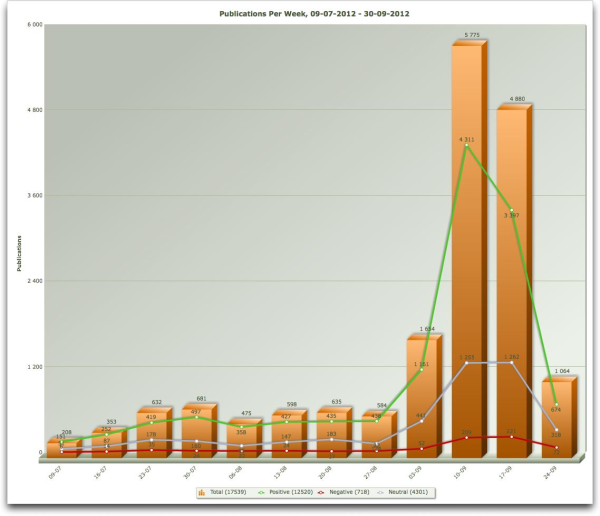
Note that the last week shown is incomplete which explains the drop. In this report we excluded Twitter to only look at blog, journals, news sites and other sources on the web.
You see the enormous increase in the amount of buzz around the introduction of the iPhone 5 on September, 12th 2012 with a large share of positive publications. We can zoom in to look at the publications per day and plot Apple’s share price in the same graph. Notice the rise in stock price after the product launch and the drop in publications in the weekend
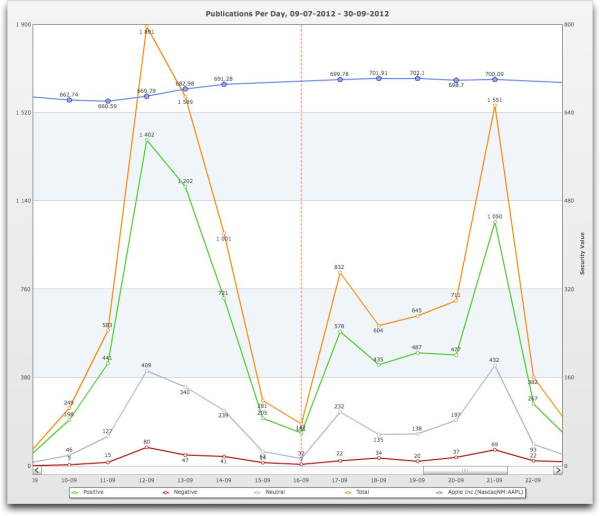
There is also criticism, such as about the iPhone Maps app which we can find if we drill down into the BuzzEvents (not shown here), but the overall sentiment is very positive.
Introducing mood states
So far we’ve looked at the polarity of a given text, whether it’s positive, negative or neutral, but we can also look in a more advanced “beyond polarity” way at sentiment. BuzzTalk can also detect emotional states in a document. We call these “mood states” which are long feeling-states. There are numerous approaches for assessing mood states and measuring their fluctuations over time, but the most widely accepted method is the Profile of Mood States (POMS) which was developed by McNair, Lorr and Droppleman. POMS measures six different mood states:
- Anger – Hostility (the strong feeling a person gets when he/she thinks someone has treated him/her badly or unfairly; the intensity of anger can vary from being mildly irritated to rage or fury).
- Tension – Anxiety (a constant feeling of overwhelming worry).
- Fatigue – Inertia (physical or mental weariness resulting from exertion).
- Confusion – Bewilderment (feelings of bewilderment, uncertainty, a general failure to control attention and emotions).
- Depression – Dejection (a condition in which a person feels discouraged, sad, hopeless, unmotivated, or disinterested in life in general).
- Vigor – Activity (feelings of mental and physical energy).
We conclude this demo of automated sentiment detection with the mood states surrounding the launch of the iPhone 5.
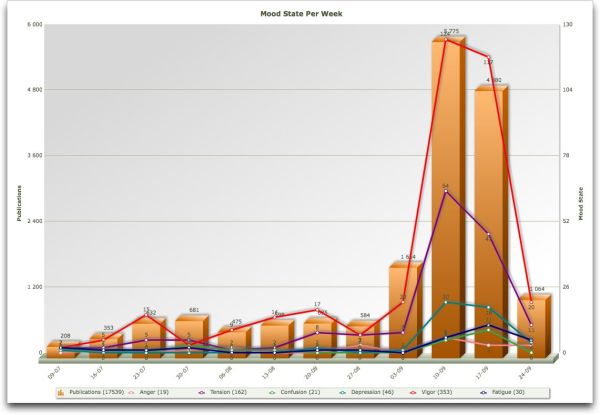
The main emotion is vigor, followed by tension. Tension is often seen when something is about to happen and the iPhone 5 is a very much hyped product of course. Interestingly enough we see a small rise in fatigue immediately after the introduction. Which is not too surprising as you have to wait for hours in line ;-).
Business applications of sentiment tracking
BuzzTalk allows businesses to track brand perception, (new) product perception, measure marketing effectiveness and of course assess and compare their reputation.

Recent Comments